NBI Background
The National Bridge Inventory (NBI) is a program of the Federal Highway Administration which is an agency within the U.S Department of Transportation. The NBI makes available records and statistics about all the bridges in the United States which includes information about bridge location, integrity, inspection history and usage.
Potential encoding discrepancy
As a side project I have been working on creating a more exhaustive Python package for parsing NBI data. This is mainly focused on decoding the numerical representations present in data files to their semantic meanings specified in the NBI documentation.
I ran into errors when trying to decode the state code fields, which based on the available documentation uses the coding table below.
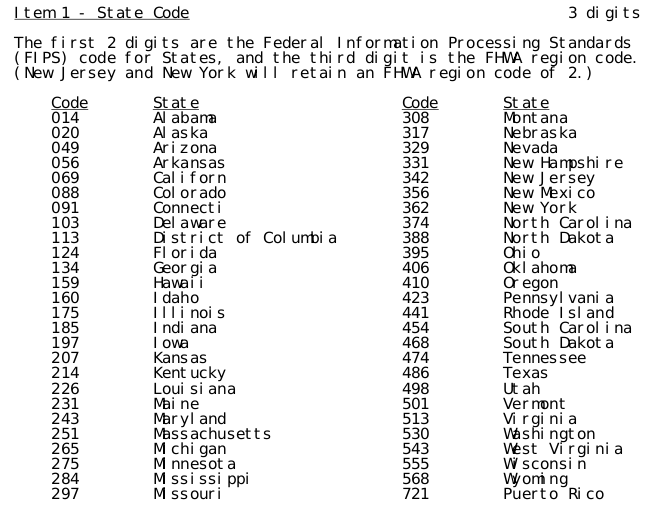
The documentation states the state code will contain three digits, but a quick check of the csv file I was using revealed most state codes had at most 2 digits.
I wanted to see if this might be true in more files hosted by NBI and so I quickly threw together a Python script to test if this two digit encoding was present in other csv files.
The script just looks to see if what is stored in the state code field of a csv file matches any code in the documentation. The results from three files are below.
Delim file tests
================
1995.txt: 0 matches and 680662 mismatches
2000.txt: 0 matches and 691060 mismatches
2019HwyBridgesDelimitedAllStates.txt: 0 matches and 617085 mismatches
No state codes in these three files matched the codes from the documentation. However NBI also provides undelimited files, which I believe was the original format as the documentation implies this encoding. Since there is no delimiter, state code is defined as the first three digits in a line.
Undelim file tests
==================
WI19.txt: 14249 matches and 0 mismatches
WY19.txt: 0 matches and 3114 mismatches
MT19.txt: 5278 matches and 0 mismatches
NC19.txt: 18407 matches and 0 mismatches
WV19.txt: 7291 matches and 0 mismatches
ND19.txt: 4329 matches and 0 mismatches
al95.txt: 16576 matches and 0 mismatches
ak95.txt: 1451 matches and 0 mismatches
Except for WY19, state codes match.
There is another later (but undated) piece of documentation titled Specification for the National Bridge Inventory Bridge Elements which includes a different encoding for state codes which is shown below.
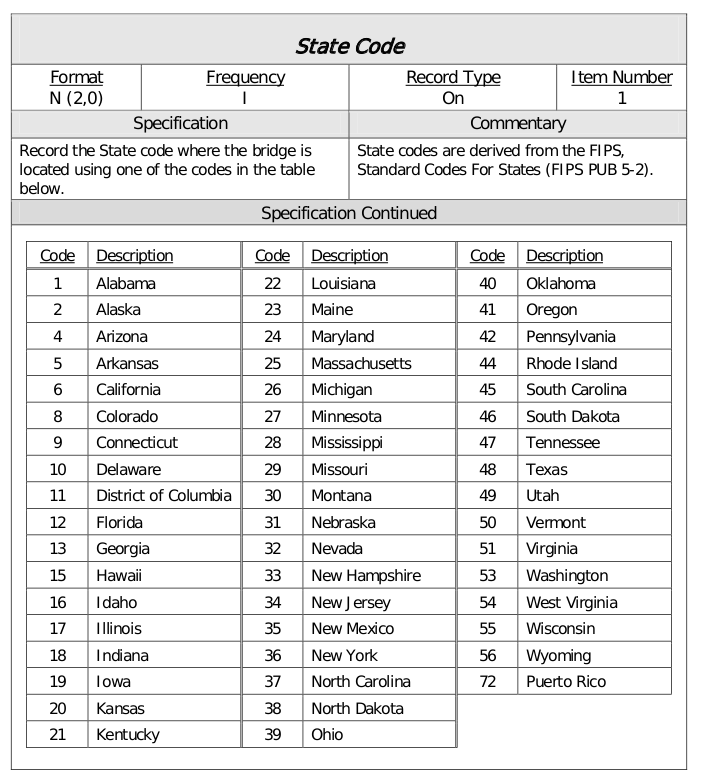
These encodings seem to match better if you do not consider leading zeros, but they will not work for undelimited files.
Based on these antidotal results, it looks like there could have been an undocumented change in encoding schemes when files where made available in csv format, or a bug in the code used to do the conversion.
Who cares? Is this a problem?
This is in all likelihood not a big deal, but I am a nerd and spent an hour or two looking into it. This is likely just a case of a lack of documentation of small change in encoding practices. However, this data is used by researchers and regulators to understand the state of America’s infrastructure and therefore its representation should be as accurate and true to reality as possible. So at the very least I think it iw worth thinking about.
Update
I got a very timely response from Samantha Lubkin at the FHWA relating to the state encodings.
The State Code as defined in the NBI Coding Guide includes a 3rd digit that is currently obsolete.
That digit is omitted from the delimited file, and can be ignored in the
nondelimited file. Aside from that 3rd digit, the codes are identical between
the SNBIBE and the NBI Coding Guide. (And both are based on FIPS.) Whether
this kind of logic exists for other fields, I can’t say.
But yes, the NBI Coding Guide is the appropriate reference for
both delimited and nondelimited NBI files.
Looks like it was a one-ff thing with just state codes. Thanks again Samantha!